124
Ogledov

Nazadnje posodobljeno dne

Ena največjih napak za lastnike novih spletnih strani je, da ne iščejo svoje datoteke robots.txt. Kaj je torej vseeno in zakaj tako pomembno? Imamo vaše odgovore.
Če imate lastno spletno mesto in vam je mar za SEO zdravje vašega spletnega mesta, se morate dobro seznaniti z datoteko robots.txt na vaši domeni. Verjeli ali ne, to je moteče veliko število ljudi, ki hitro zaženejo domeno, namestijo hitro spletno mesto WordPress in se nikoli ne trudijo, da bi karkoli naredili s svojo datoteko robots.txt.
To je nevarno. Slabo konfigurirana datoteka robots.txt lahko dejansko uniči zdravje vašega spletnega mesta in škodi vsem možnostim za povečanje prometa.
The Robots.txt Datoteka je pravilno imenovana, ker gre v bistvu za datoteko, ki vsebuje direktive za spletne robote (kot so roboti iskalnika) o tem, kako in kaj lahko plazijo na vašem spletnem mestu. To je spletni standard, ki mu sledijo spletna mesta od leta 1994, vsi večji pajki pa se držijo standarda.
Datoteka je shranjena v besedilni obliki (s pripono .txt) v korenski mapi vašega spletnega mesta. Pravzaprav si lahko ogledate datoteko robot.txt katerega koli spletnega mesta le tako, da vtipkate domeno in /robots.txt. Če poskusite to z groovyPost, boste videli primer dobro strukturirane datoteke robot.txt.
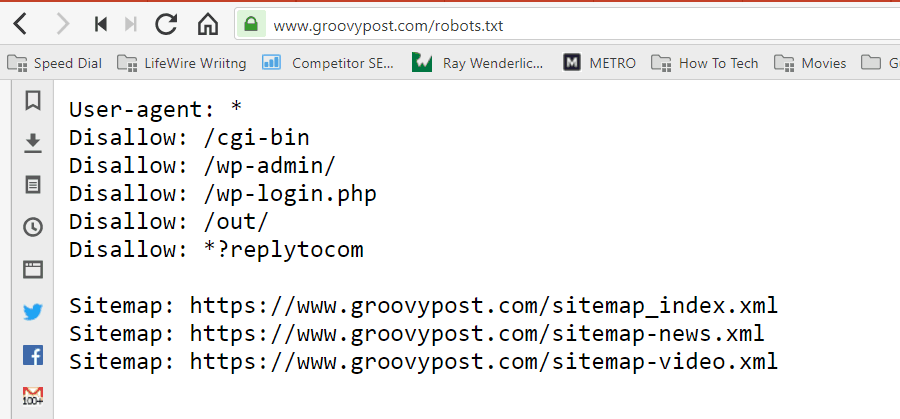
Datoteka je preprosta, vendar učinkovita. Ta primer datoteke ne razlikuje med roboti. Ukazi se izdajo vsem robotom z uporabo Uporabniški agent: * direktiva. To pomeni, da vsi ukazi, ki mu sledijo, veljajo za vse robote, ki obiščejo spletno mesto, da ga prelistajo.
Prav tako lahko določite posebna pravila za določene spletne pajke. Na primer, lahko dovolite Googlu (Googlovemu pajku), da pregleduje vse članke na vašem spletnem mestu, vendar boste morda želeli onemogoči ruskemu pajku Yandex Bot, da ne plazira članke na vašem spletnem mestu, o katerih so omalovažujoče informacije Rusija.
Obstaja na stotine pajkov, ki brskajo po internetu za informacijami o spletnih mestih, vendar je naštetih 10 najpogostejših, ki bi vas morali skrbeti.
Primer zgornjega primera, če želite Googlu dovoliti, da indeksira vse na vašem spletnem mestu, vendar želite blokirajte Yandex, da ne bo indeksiral vsebine člankov na ruskem jeziku, v robots.txt dodate naslednje vrstice mapa.
Uporabniško sredstvo: googlebot
Onemogoči: Onemogoči: / wp-admin /
Onemogoči: /wp-login.php
Uporabniško sredstvo: yandexbot
Onemogoči: Onemogoči: / wp-admin /
Onemogoči: /wp-login.php
Prekini: / rusija /
Kot lahko vidite, prvi odsek blokira Google le, da se plazi po vaši prijavni strani WordPress in skrbniških straneh. Drugi razdelek blokira Yandex iz istega, pa tudi celotnega območja vašega spletnega mesta, kjer ste objavili članke z protirusko vsebino.
To je preprost primer, kako lahko uporabite Ne dovoli ukaz za nadzor določenih spletnih pajkov, ki obiščejo vaše spletno mesto.
Disallow ni edini ukaz, do katerega imate dostop v datoteki robots.txt. Uporabite lahko tudi kateri koli drugi ukaz, ki bo usmeril, kako robot lahko plazi po vašem spletnem mestu.
Upoštevajte, da boti bodo samo poslušajte ukaze, ki ste jih dali, ko določite ime bot.
Pogosta napaka, ki jo ljudje delajo, je prepoved območja, kot je / wp-admin /, iz vseh botov, nato pa določi razdelek googlebot in izključi le druga področja (na primer / približno /).
Ker boti sledijo samo ukazom, ki ste jih določili v njihovem razdelku, morate znova zagnati vse ostale ukaze, ki ste jih določili za vse bote (z uporabo * user-agent-a).
Upoštevajte, da naj bi robots.txt pomagal legitimnim botom (kot so boti iskalnikov) učinkovitejšega iskanja vsebine po vašem spletnem mestu.
Obstaja veliko zloglasnih pajkov, ki se plazijo po vašem spletnem mestu, da naredijo stvari, kot so strganje e-poštnih naslovov ali krajo vaše vsebine. Če želite poskusiti in uporabiti datoteko robots.txt, s katero preprečite, da bi ti pajki iskali karkoli na vašem spletnem mestu, ne moti. Ustvarjalci teh pajkov običajno ignorirajo vse, kar ste dali v datoteko robots.txt.
Pri večini lastnikov spletnih strani je Googlov iskalnik iskal čim več kakovostne vsebine na vašem spletnem mestu.
Vendar Google porabi le omejeno brskaj po proračunu in hitrost plazenja na posameznih mestih. Stopnja pajka je, koliko zahtev na sekundo bo Googlebot vložil na vaše spletno mesto med pajkanjem.
Pomembnejši je proračun za pajkanje, to je koliko skupnih zahtev, ki jih bo Googlebot vložil za pajkanje vašega spletnega mesta v eni seji. Google "porabi" proračun za pajkanje tako, da se osredotoči na področja vašega spletnega mesta, ki so zelo priljubljena ali so se pred kratkim spremenila.
Nisi slep do teh informacij. Če obiščete Google Orodja za spletne skrbnike, lahko vidite, kako pajek ravna z vašim spletnim mestom.
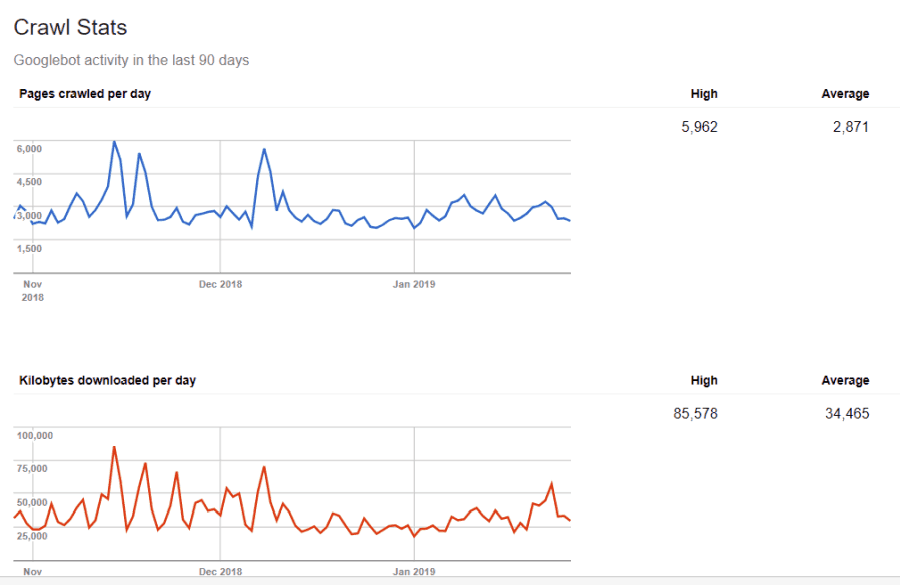
Kot lahko vidite, pajka vsak dan ohranja svojo aktivnost na vašem spletnem mestu precej konstantno. Ne lovi se vseh spletnih mest, ampak samo tiste, ki se jim zdijo najpomembnejše.
Zakaj bi to prepustili Googlu, da sam odloči, kaj je pomembno na vašem spletnem mestu, ko lahko s svojo datoteko robots.txt poveste, katere so najpomembnejše strani? Tako bo Googlebot preprečil izgubo časa na straneh z nizko vrednostjo na vašem spletnem mestu.
Google Webmaster Tools omogoča tudi preverjanje, ali Googlebot dobro bere vašo datoteko robots.txt in ali obstajajo napake.
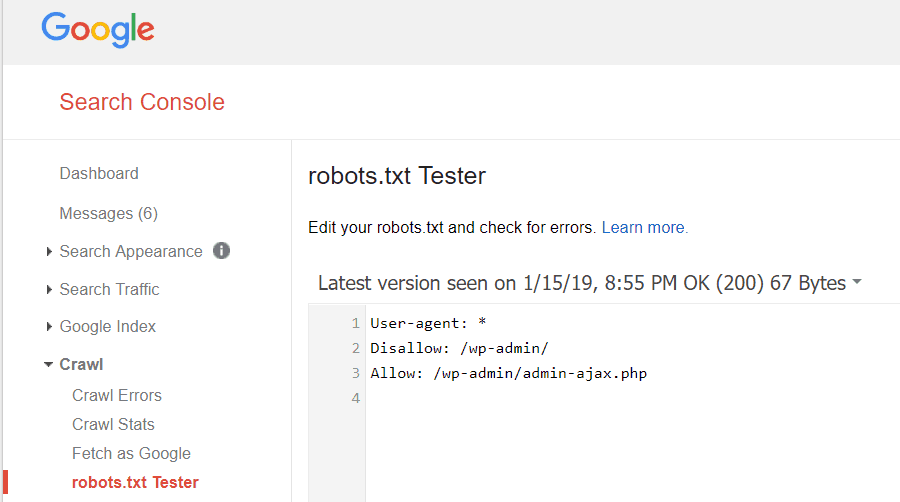
Tako boste lahko preverili, da ste pravilno strukturirali datoteko robots.txt.
Katere strani ne smete onemogočiti iz Googla? Dobro je, da SEO vaše spletne strani onemogoči naslednje kategorije strani.
Največja napaka, ki jo naredijo novi lastniki spletnih strani, je, da sploh ne pogledajo svoje datoteke robots.txt. Najslabša situacija bi lahko bila, da datoteka robots.txt dejansko preprečuje, da bi se vaše spletno mesto ali območja vašega spletnega mesta sploh izognili.
Preverite datoteko robots.txt in se prepričajte, da je optimizirana. Tako Google in drugi pomembni iskalniki s svojim spletnim mestom "vidijo" vse čudovite stvari, ki jih ponujate svetu.

